— он же импорт в Jira в — это дело серьезное. В было показано, как создавать (они же issues) в Jira поодиночке с помощью , но это все для любителей садомазо и ради констатации самого , что создавать одиночные задачи можно не только с помощью самой Jira, но и с внешних (да хоть из , открытого в Microsoft™ Word), прописывая в необходимые . Но ни один вменяемый руководитель проекта, или главный конструктор не...
И тут сам себя поймал на вранье 🤪 Подавляющее большинство любой степени сложности в нашем благословенном государстве занимается именно тем, что вводит задачи Jira, Redmain, Bitrix24 или MS Project . Покажем, как и всего за несколько минут создать в Jira сразу аж целых 95 задач, причем полностью соответствующих требованиям стандарта. И заполучить на выходе красивую , изображенную на ниже. Редакция от 22.12.2024.
Создан 07.09.2020 14:51:09
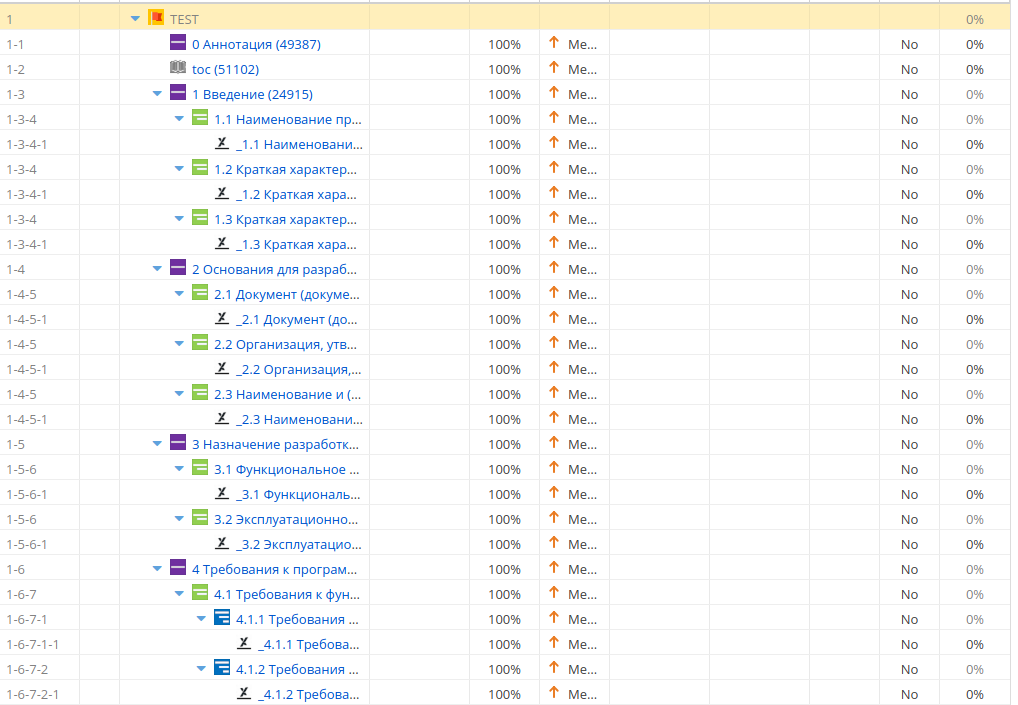
Пакетный импорт задач в Jira можно организовать, только имея, что импортировать. Автор решил импортировать на по . Можно возразить — но это же документ! На что можно возразить встречно — но разделы, подразделы, пункты и подпункты кто–то же должен разрабатывать–заполнять? Следовательно, заполнение каждого раздела, подраздела, пункта или подпункта надо на кого–то повесить, кому–то назначить. А назначают задачи, , . Одним словом — различные ради получения ожидаемого .
Автор, разумеется, располагает готовыми структурами практически всех мыслимых и немыслимых видов документов по ГОСТ 2, ГОСТ 15, ГОСТ 19, ГОСТ 24, ГОСТ 34 и РД 50–34.698–90, в его рабочего инструмента — AuthorIT, поэтому использовать любую из них особого труда не составило — проблема только в выборе. Но чтобы «скормить» Jira хоть что–нибудь, необходимо преобразовать структуру документа в текстовый формат csv. Есть, конечно, всяческие прибамбасы, позволяющие Jira импортировать документы других форматов, но в минимальную «поставку» Jira они не входят, а доверять стороннему ПО как–то нет склонности. Поэтому структура технического задания была опубликована в формат XML средствами AuthorIT, затем (с помощью Altova XMLSpy) был скорректирован родной файл преобразования XSLT, чтобы на выходе образовалась такая вот формата HTML, см. рисунок ниже.
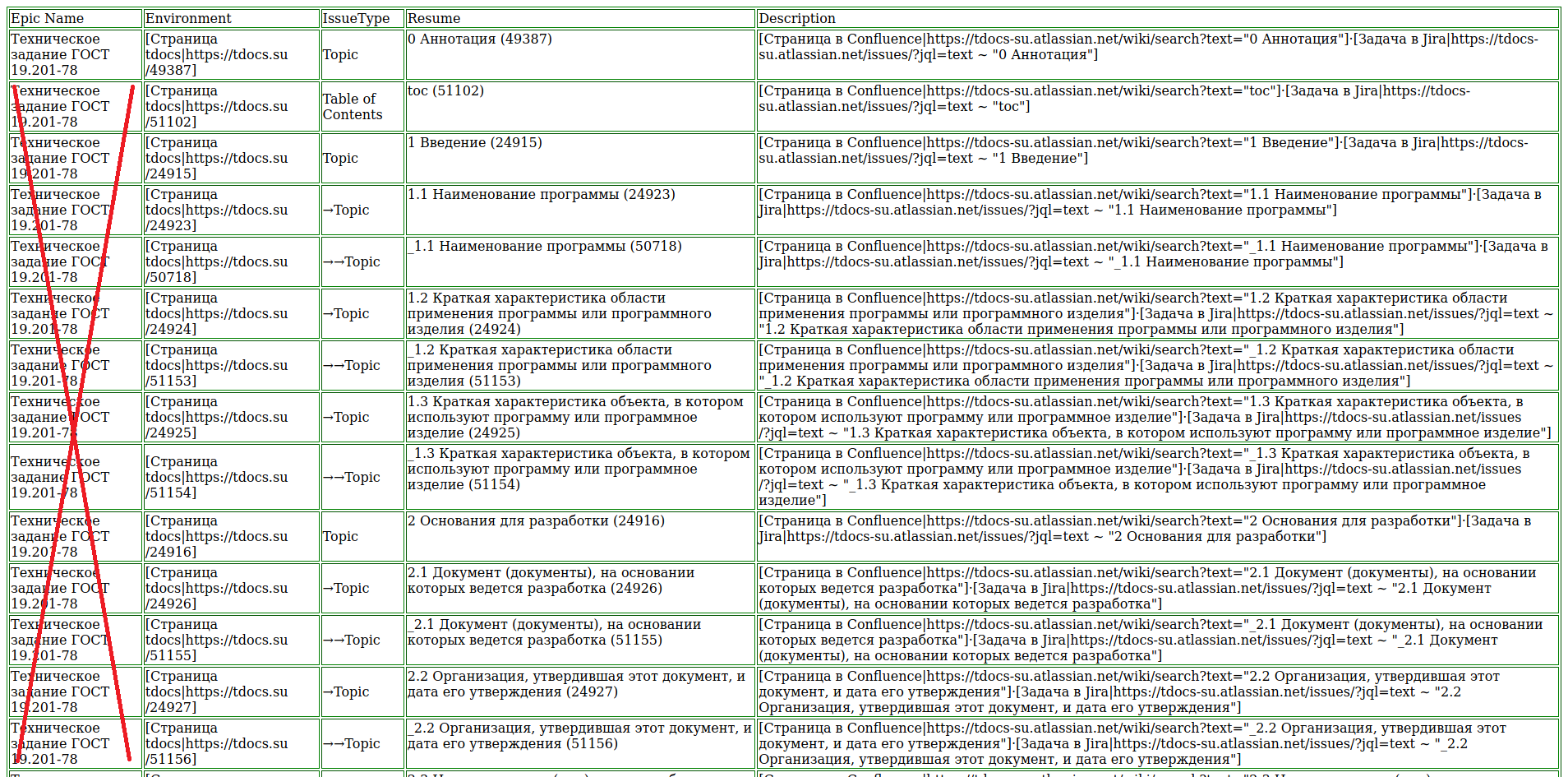
Пара слов о таблицы. Поля Environment и Description содержат автоматически формируемые ссылки, позволяющие открыть в созданной задаче либо страницу первоисточника на этом портале, либо поискать связанную с задачей страницу Atlassian Confluence. Если она есть, то немедленно найдется, если нет, то можно ее и создать.
Поле IssueType особо хитрое: в нем стрелочки показывают топиков в структуре документа. В Jira каждому уровню соответствуют задачи, обозначенные  ,
,  ,
,  и
и  . Число полосочек соответствует уровню вложенности 🤪
. Число полосочек соответствует уровню вложенности 🤪
А топикам, содержащим первым символом в своем заголовке знак подчеркивания, соответствует пиктограмма 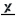 . Это означает, что топик в Microsoft™ Word должен отображаться без , подобно обычному .
. Это означает, что топик в Microsoft™ Word должен отображаться без , подобно обычному .
Ну и все. Табличка преобразуется в текст формата csv хоть экселем, хоть опенофисным Calc'ом — да чем угодно. Файл, полностью готовый к импорту в Jira, изображен на рисунке ниже.
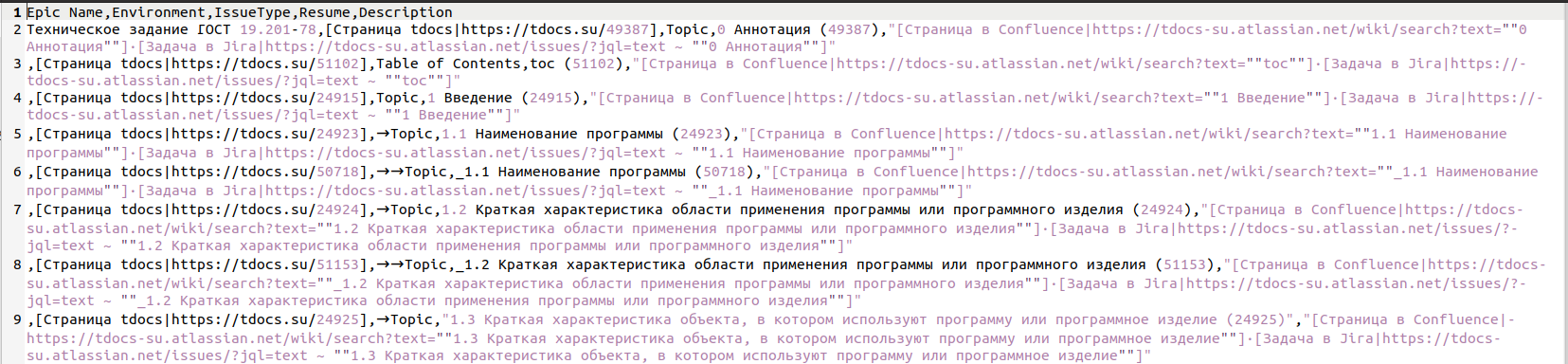
Ну а дальше собственно об импорте в Jira.
Процесс импорта из CSV–файла и автоматического создания задач Jira (issues)
Процесс импорта из CSV–файла и автоматического создания задач Jira (issues) проводится в несколько этапов, рассмотрим только самые основные.
Первый и самый важный — это сопоставление полей CSV полям Jira. Доподлинно автору неизвестно, как именно Jira оперирует с CSV–файлом, но есть подозрение, что читает каждую его отдельно и создает из нее соответствующую в таблице БД. Просто, тупо и последовательно, иначе была бы возможность восстановить из CSV–файла фактические связи между задачами. Но этого не происходит, а жаль.
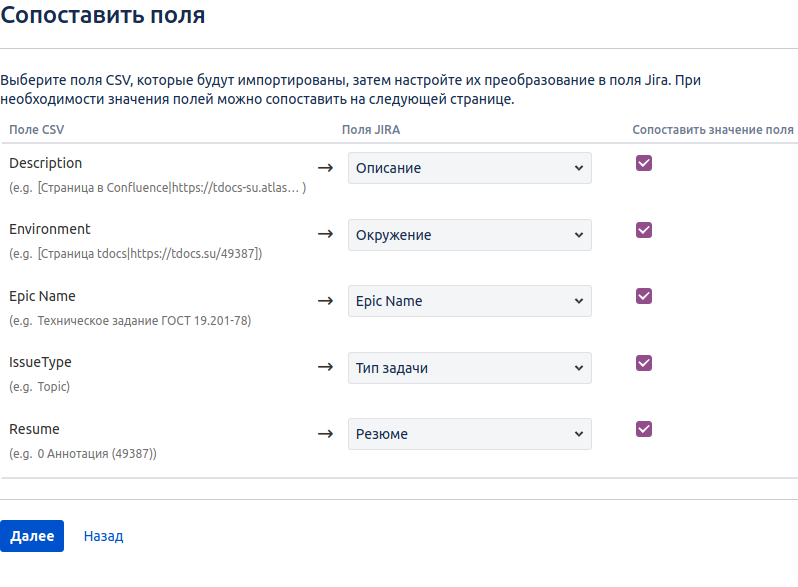
Схема сопоставления полей на рисунке выше более чем очевидна.
Следующим этапом проходит сопоставление типов задач.
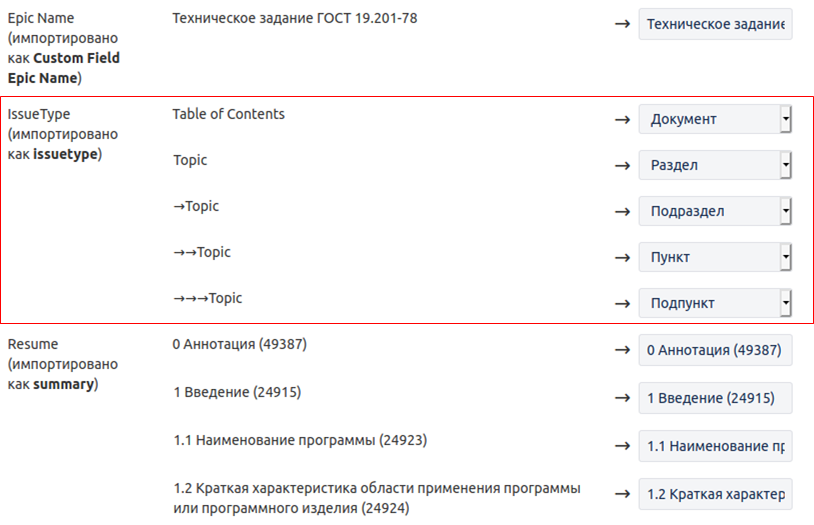
Здесь тоже все очевидно. После полной загрузки задач можно создать диаграмму Гантта из фильтра задач, на выходе получается нечто разноцветно–бестолковое, см. рисунок ниже.
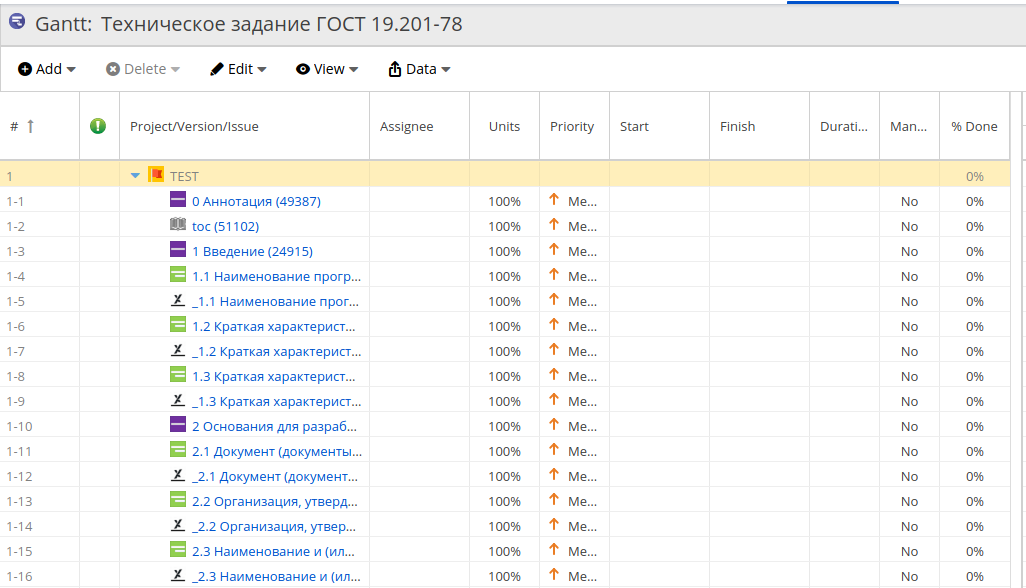
Зато видно, как и какую из созданных задач «индентить», т.е. сдвигать вправо по подчиненности. Помимо черточек на пиктограммах есть еще и номера разделов, подразделов и т.п. в заголовках, тут уж никак не запутаться. Кстати, бывало и так, что Jira сортировала задачи в каком–то одном ей свойственном и очевидном порядке. Разгрести потом все это вручную почти немыслимо, если не указать заранее номера элементов структуры.
Поиск задач для изменения их типа
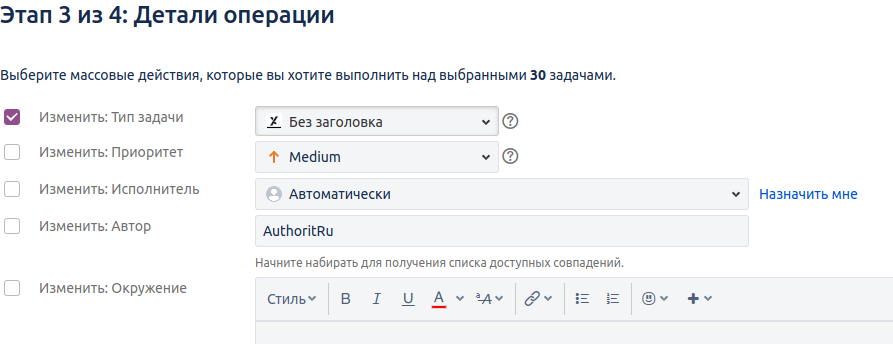
Автор проскочил немного вперед: на диаграмме Гантта видны задачи, помеченные . Автоматически при импорте так не получается, поскольку XSLT не оснащен привычными функциями работы со строками. Так, к примеру, символ подчеркивания в строке разыскать легко, получить его позицию в строке — тоже, а вот... В общем, нормально разобрать строку можно, но не слишком легко, а поэтому проще воспользоваться штатными средствами Jira по пакетному преобразованию задач. Но сначала надо отыскать эти задачи, для чего запустить по параметрам, показанным на рисунке ниже.
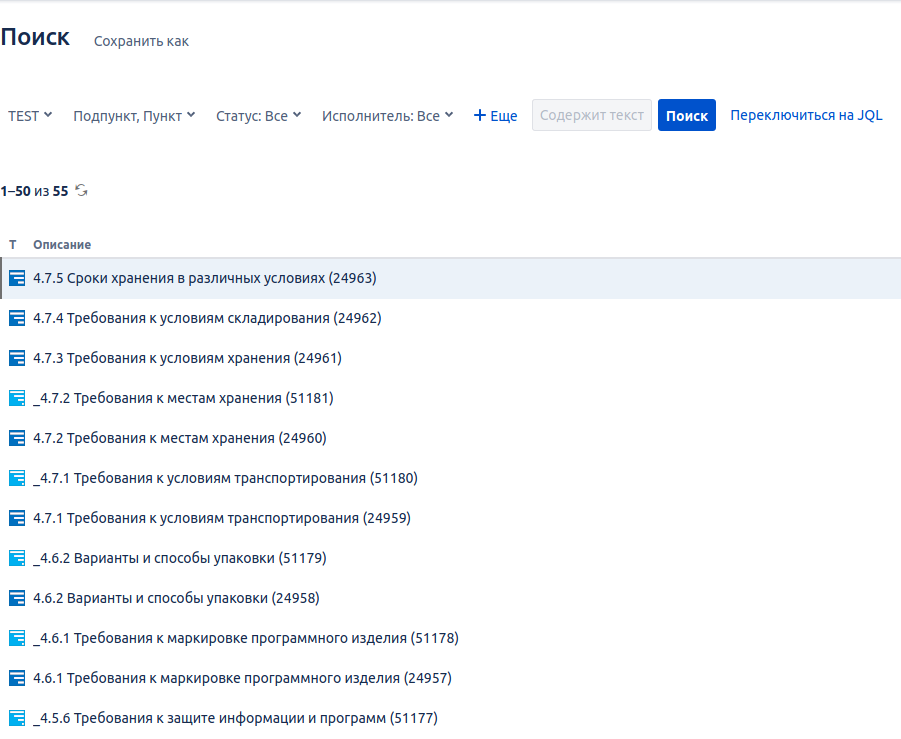
Почему–то Jira не находит символ подчеркивания в строке, хотя символ этот не является зарезервированным. Но очевидно, что первоуровневым топик с _ в начале строки быть не может, поэтому криво, но отыскивается в пунктах и подпунктах. Далее — пакетное изменение типа задач.
Пакетное изменение типа задач
Здесь все просто. Сначала выбираем из найденных, помечаем соответствующие флажки,

а затем запускаем изменение.
После выполнения указанных процедур диаграмма Гантта будет выглядеть так, как показано в конце подраздела Процесс импорта из CSV–файла и автоматического создания задач Jira (issues).
Мораль (результат деятельности)
Получить красивую диаграмму Гантта, подобную этой, легко. Надо вручную разнести задачи по уровням их иерархии. Занятие весьма увлекательное, подобное «грызне» семечек или лопанию пузырьков полиэтиленовой упаковки. Говорят, что это самые лучшие в мире антидепрессанты 😉
И немного о задачах, сформированных Jira. Открываем первую попавшуюся и видим, что
-jira.png)
- в поле Описание имеются готовые автоматически созданные ссылки:
- первая выводит на cвязанную с задачей страницу в Atlassian Confluence, мгновенно ее находит, если таковая уже имеется. Или стимулирует к созданию страницы и привязке ее к задаче Jira;
- вторая (зачем–то) открывает текущую задачу, т.е. саму себя. Ну пусть будет — избыток рождает качество 🤪
- видна задач в виде родителей и потомков;
- но куда–то пропало поле Окружение (с этим придется разбираться отдельно) — [РЕШЕНО] — в поле Epic Name необходимо вручную удалить все записи, кроме самой первой, см. зеленую табличку в Пакетный импорт задач в Jira. Теперь в этом поле имеется ссылка на первоисточник — элемент структуры нормативного документа.
Остается только назначить задаче исполнителя, сроки выполнения и приоритет. И так по каждой из импортированных 95 задач, поскольку сроки и ФИО конкретных исполнителей изначально нам неизвестны.
Как–то так. Выяснилось, что значительно проще разок поработать головой, чем 95 раз руками.
 автоматизированной измерительно–информационной системы коммерческого учета электроэнергии (АИИС КУЭ)")
 автоматизированной измерительно–информационной системы коммерческого учета электроэнергии (АИИС КУЭ) (пример)")
 автоматизированной измерительно–информационной системы коммерческого учета электроэнергии (АИИС КУЭ) (пример)")
 автоматизированной измерительно–информационной системы коммерческого учета электроэнергии (АИИС КУЭ) (пример)")
 автоматизированной измерительно–информационной системы коммерческого учета электроэнергии (АИИС КУЭ) (пример)")
 автоматизированной измерительно–информационной системы коммерческого учета электроэнергии (АИИС КУЭ) (пример)")
 Интернет–портала (пример)")

